∇-Nabla: Numerical Analysis BAsed LAnguage
 |
 |
 |
 |
 |
 |
 |
 |
Motivations
Addressing the major challenges of software productivity and performance portability is becoming necessary to take advantage of emerging extreme-scale computing architectures. As software development costs will continuously increase to address exascale hardware issues, higher-level programming abstraction will facilitate the path to go. There is a growing demand for new programming environments in order to improve scientific productivity, to facilitate the design and implementation, and to optimize large production codes.
∇ language
In this context, the numerical-analysis specific language ∇ improves applied mathematicians productivity throughput and enables new algorithmic developments for the construction of hierarchical and composable high-performance scientific applications.
The introduction of the hierarchical logical time within the high-performance computing scientific community represents an innovation that addresses the major exascale challenges. This new dimension to parallelism is explicitly expressed to go beyond the classical single-program-multiple-data or bulk-synchronous-parallel programming models. Control and data concurrencies are combined consistently to achieve statically analyzable transformations and efficient code generation. Shifting the complexity to ∇'s compiler offers an ease of programming and a more intuitive approach, while reaching the ability to target new hardware and leading to performance portability.
∇ Toolchain
The ∇ toolchain is composed of three main parts:
- the front-end raises the level of abstraction with its grammar;
- the back-ends hold the effective generation stages,
- the middle-end can provide agile software engineering practices transparently to the application developer, such as: instrumentation (performance analysis, V&V, debugging at scale), data or resource optimization techniques (layout, locality, prefetching, caches awareness, vectorization, loop fusion) and the management of the hierarchical logical time which produces the graphs of all parallel tasks.
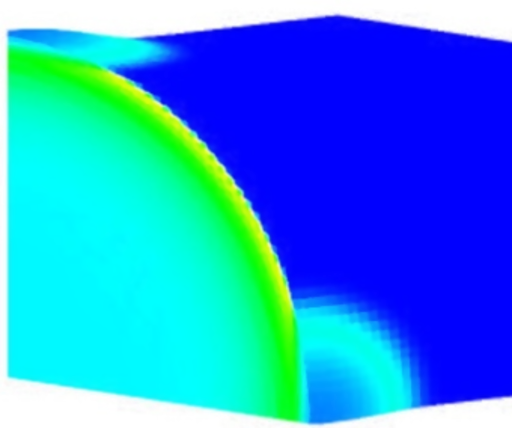
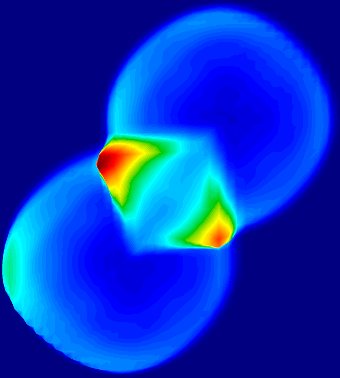
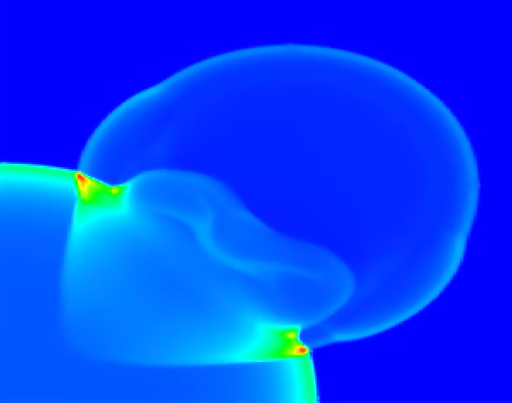
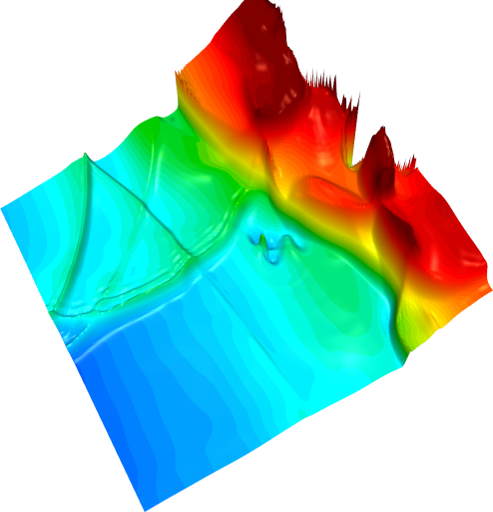
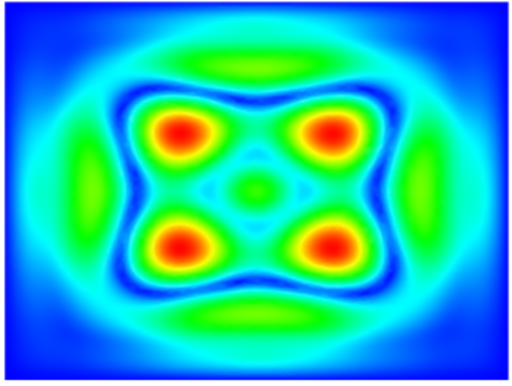
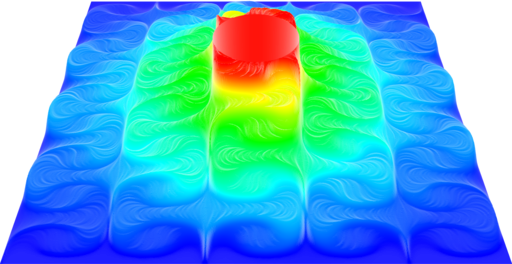
As a demonstration of the potential and the efficiency of this approach, several benchmark implementations are given in example and their performances can be evaluated over a variety of hardware architectures (Xeon, XeonPHI and CUDA).
Raising the level of abstractions allows the framework to be prepared to address growing concerns of future systems. The generation stages will be able to incorporate and exploit algorithmic or low-level resiliency methods by coordinating co-designed techniques between the software stack and the underlying runtime system.